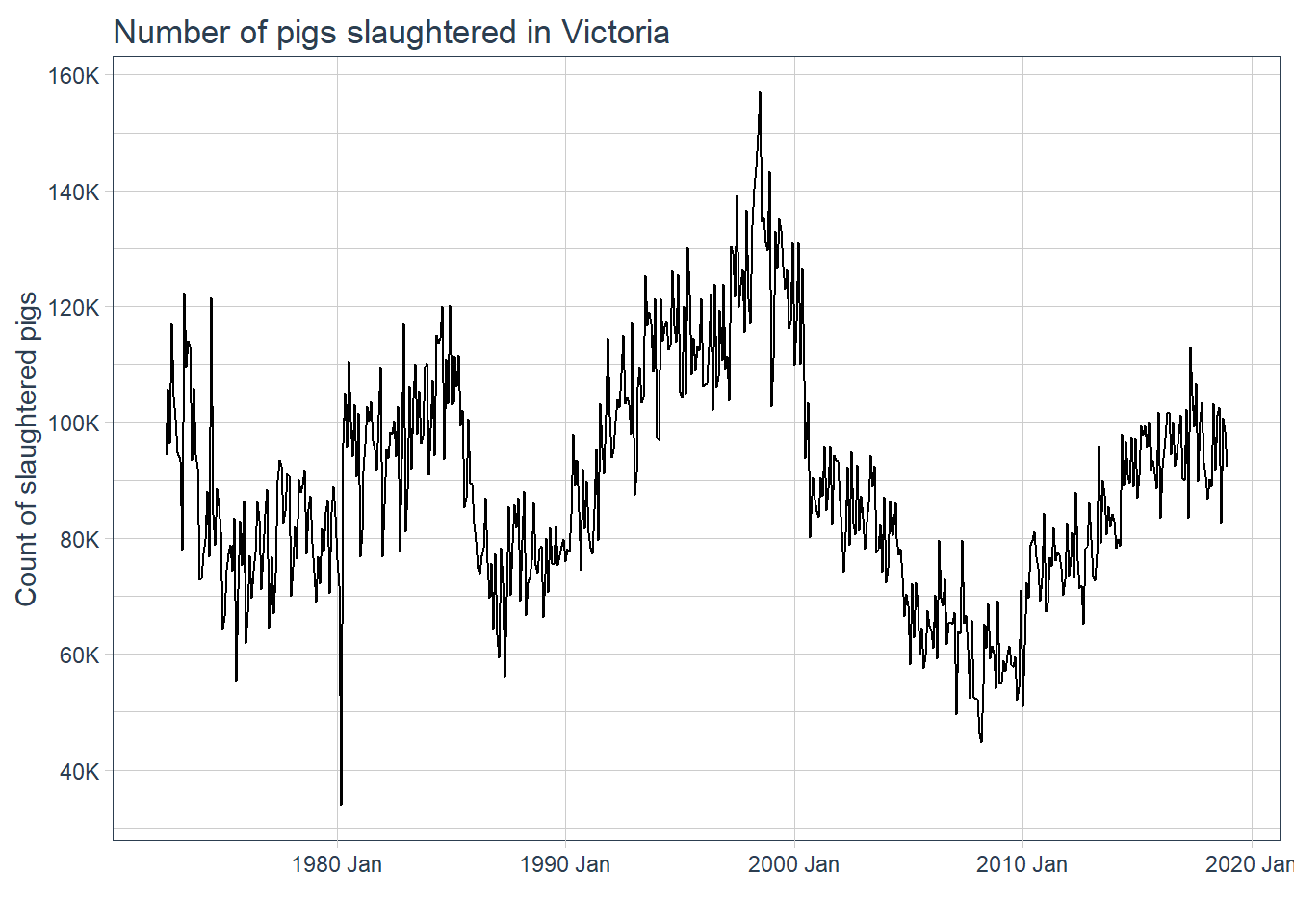As I’ve said in one of my previous posts, Rob J. Hyndman has excellent book on forecasting that is full of exercises by the end of each chapter. One of those chapters - to be more precise, Chapter 8 - Exponential Smoothing - has tasks that require the implementation of ETS. This really helped me to understand ETS. But, before I go into that part, let’s see what theory says about ETS.
Exponential smoothing was proposed in the late 1950s (Brown, 1959; Holt, 1957; Winters, 1960), and has motivated some of the most successful forecasting methods. Forecasts produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older. In other words, the more recent the observation the higher the associated weight. This framework generates reliable forecasts quickly and for a wide range of time series, which is a great advantage and of major importance to applications in industry.
He also goes on to say that ETS (to be more precise, SES or simple exponential smoothing) is most suitable for forecasting data with no clear trend or seasonal pattern. The math behind the ETS is presented in 2 ways: through weighted average form and through component form. From the programming standpoint, I like component form better, but let’s present both approaches.
Meaning of these mathematical symbols is as follows:
\(\hat{y}_{T+1|T}\): first (forecasted) future value (\(T+1\)), given last historical value (\(T\)).
\(\hat{y}_{T}\): last historical value.
\(\hat{y}_{T|T-1}\): last forecasted value at index \(T\). Spoiler alert: this is where magic happens.
\(\alpha{}\): smoothing parameter.
\(\hat{y}_{T|T-1}\) is where the magic happens. Fitted values in ETS are one-step forecasts of the training data, and by deduction we can conclude that:
Hold your horses, you’re probably having questions about \(\mathcal{l}_{0}\). We will get to that term in a minute, but when you see this term, read it as starting value.
2.2 Component form
The component form will get us to the same results, but it’s actually easier to see what is really going on. It consists of one simple equation, which we (surprise, surprise) call the forecast equation:
\[ \hat{y}_{t+h|t} = \mathcal{l}_{t} \tag{3}\] Same as before: future value, given the historical value (\(\hat{y}_{t+h|t}\)) is equal to \(\mathcal{l}_{t}\). But what is that? That we call the smoothing equation, and it’s given by the following formula:
This is identical to the first formula in the weighted form, only the symbols are different. That’s it.
Okay, enough with the theory. Let’s implement this.
3 Implementation
Exercise 1 is as follows:
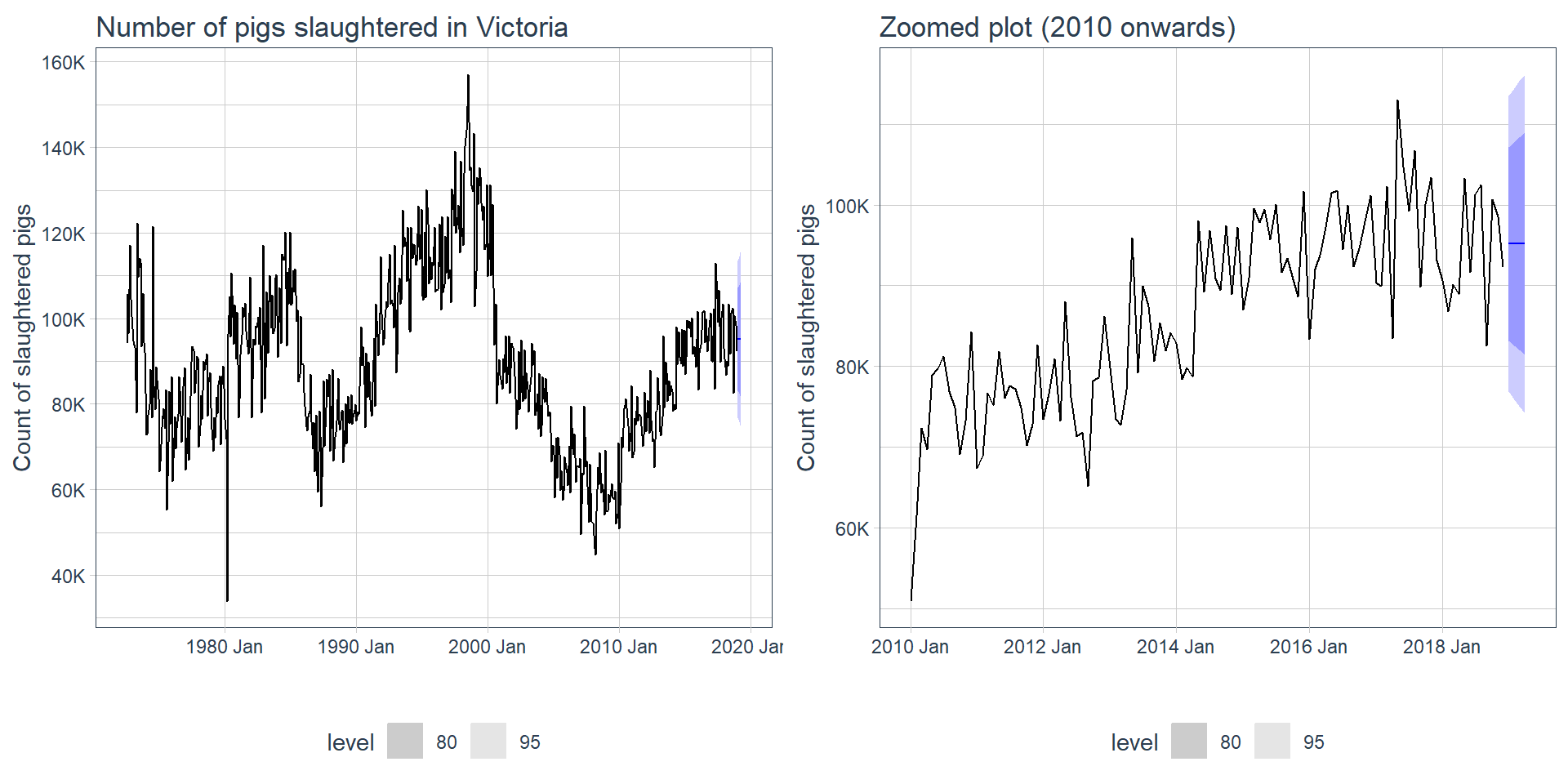
Consider the the number of pigs slaughtered in Victoria, available in the aus_livestock dataset. Use the ETS() function to estimate the equivalent model for simple exponential smoothing. Find the optimal values of \(\alpha{}\) and \(\mathcal{l}_{0}\), and generate forecasts for the next four months.
tidyverse and fpp3 is loaded, so we can go on with the solution.
aus_pigs <- aus_livestock %>%filter(str_detect(Animal, "Pigs") &str_detect(State, "Victoria")) %>%select(Month, Count)autoplot(aus_pigs, .vars = Count) +scale_y_continuous(labels = scales::label_comma(1, scale =1/1e3, suffix ="K"),breaks =seq(0, 200e3, 20000)) +labs(y ="Count of slaughtered pigs", x ="",title ="Number of pigs slaughtered in Victoria")
Let’s forecast with ETS using tools from fable:
fit <- aus_pigs %>%model(ETS(Count ~error("A") +trend("N") +season("N")))report(fit)
Remember those \(\mathcal{l}_{0}\) and \(\alpha{}\) values from theory? Well, here they are again. The point of ETS is to optimize those parameters so that Sum of Squared Errors is minimized. \(\mathcal{l}_{0}\) is the first value for the ETS model since that value cannot be given by the model. Why? For the simple reason that every forecast for ETS model requires last historical data. First historical value (or first point in training time series data) does not have any, so we need \(\mathcal{l}_{0}\).
So, we will need to find \(\mathcal{l}_{0}\)and\(\alpha{}\) that will give us minimum of sum of squared errors, where error is defined as \((y - \hat{y})^2\).
The optim() requires starting values for it’s algorithms. For \(\alpha{}\), I’ve decided to go with 0.5, while for \(\mathcal{l}_0\), first historical value should be fine.
# A tibble: 2 x 5
term estimate estimate_me diff_abs diff_rel
<chr> <dbl> <dbl> <dbl> <dbl>
1 alpha 0.322 0.322 0 0
2 l[0] 100647. 99223. 1424. 0.0141
So, I’ve got \(\alpha{}\) correct - 0.322 - but I’m missing \(\mathcal{l}_{0}\) term by 1.41%. Why? Honestly, I don’t know, I would have to check the source code of fable ETS for differences or choose different optimization algorithm from optim(). But, this is good enough for me, at least for the purpose of solving this exercise.
Footnotes
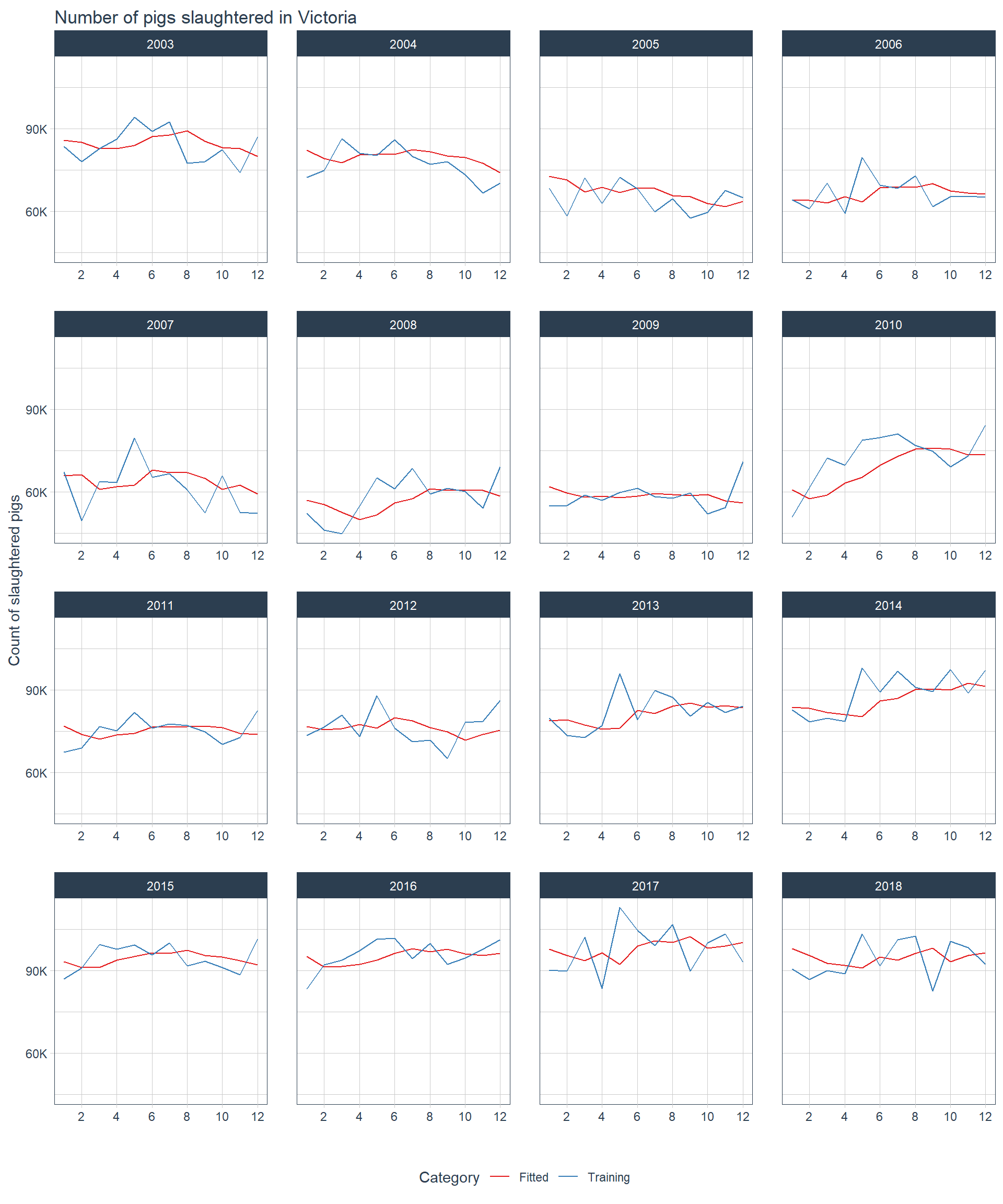
Do note that I wanted to see the performance for each year, but since the dataset is really long time-wise, I’ve decided to show period from 2003 onwards.↩︎
For more programmatically inclined readers, yes, this could have been done through recursion, but R was complaining.↩︎